Part III of building a Modern Data Platform in Azure using Terraform
Through a series of posts, we will go from nothing more than a machine that meets the minimum requirements for the azure-terraform-bootstrap to a fully functioning Enterprise-class Modern Data Platform. In our last post we walk through the architecture and code to create a headless Linux VM to support future workloads. Today we take a step back and look at the big picture and answer the question of “What exactly are we building?”
So this is the third post in the series in building a Modern Data Platform in Azure using Terraform; why are we now only getting to the architecture of what we are building? Shouldn’t we have started with this so we could plan out what we are doing? And aren’t we doing things a little backward?
So the questions above are fair; I’ll answer each of them in turn. The answer to the first question is simple we need a solid footing to start. As long as the solution involved Azure and Terraform, it didn’t really matter what we were going to build the initial Terraform setup would be the same. As to the second question, “…shouldn’t we have started with this?” While we could have started this series of posts with a high-level architecture, providing working code out of the gate is more valuable to the reader. In a sense, the title of the series is a conceptual architecture in itself “building a Modern Data Platform in Azure using Terraform.” Finally, to answer the third question, maybe we are doing things a little backward, but maybe not; we need a foundation and know that our basic building blocks of Terraform and Azure would get us there.
Logical Architecture
This diagram has seven distinct blocks. The three blocks shaded purple represent the core of the Modern Data Platform. The grey block on top accounts for various master data management capabilities we will provide in this system that could be extended to other systems outside of the Modern Data Platform. The blue block on the bottom represents the Azure guardrails we will put in place for this solution but should be present in all Azure solutions. The orange block on the left represents new or existing source data that will be stored and processed by the Modern Data Platform. The final yellow block on the right side of the diagram represents different ways that information in the modern data platform can be consumed.
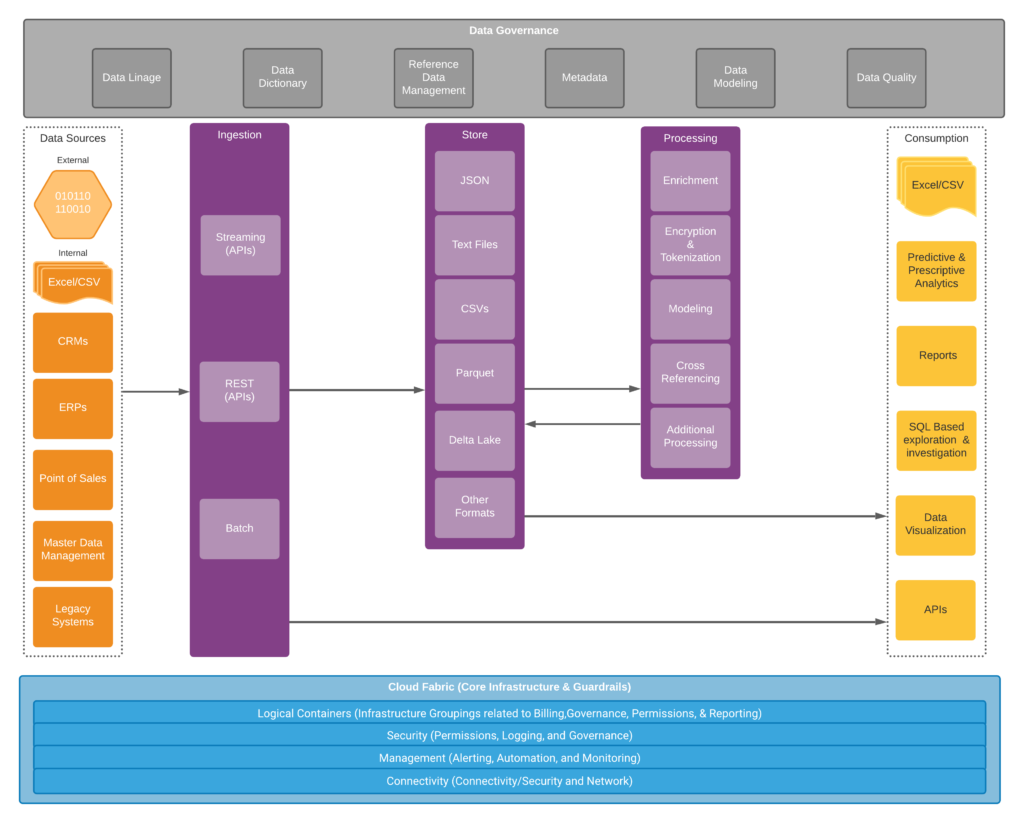
Starting at the right of the digram, the data sources block shows multiple different data sources, both internal and external, flowing the ingestion area. The ingestion capability needs to allow data to be pulled or pushed in batch or in real-time. The ingestion area is the first time data enters our system and the first time that consumption is possible in our Modern Data Platform. Data consumption is expected to be limited at this stage, most likely for either metrics or target windowed views of real-time data. The next logical step is to land that data in storage without transformation in its raw form. Loading the data from source to storage puts us firmly on the ELT path vs. the ETL path from an architecture perspective. Once again, consumption is allowed and a normal operation. Accounting for the consumption of the raw data allows organizations to solve basic data investigation issues dealing with ease of access to data and centrally locating data to allow joining data together from different sources. The third block represents data processing. This could be anything from enriching data with third-party information to transforming data into a traditional star schema model and everything in between. Finally, we have the last block, which is outside of our platform but part of the system as a whole representing all of the different mechanisms that can be used to consume the data in our Modern Data Platform. All of this core data platform is bound by Data Governance at the top, representing both logical and mechanical processes focused on the data itself and Cloud Guardrails concentrated on the configuration of the platform to manage security and costs without sacrificing flexibility, stability, and scalability.
So you have described the components at a high level, but why is this good, and how will it be different from a traditional Data Warehouse?
So it’s good because it’s more flexible from a traditional data warehouse from a purpose perspective. The Modern Data Platform can ingest raw data from multiple services and allow consumption immediately or be refined and enriched to meet data investigation, reporting, and advanced analytics needs. Implementing this architecture in the cloud allows us to take advantage of inexpensive storage as well as compute architectures that decouple the storage from the compute in ways that traditional on-premises infrastructure cannot. While it is possible to build Dynamic Compute Clusters on-premises, you still need the hardware to flex up and down on; in the end, you still have limited hardware and lead time to add more physical hardware when necessary. The cloud leaves those limitations behind, but there is a tradeoff in the cost per unit increase. However, you can turn things off in the cloud, and on-prem, you can’t, so your total cost could decrease. This sounds like I am putting forth a low-cost benefit for the cloud I am not. I’m proposing that you can now control your costs in ways you never could before, and that is the benefit. The real benefit to the cloud is that I have already stated the flexibility, reliability, performance, and ability to innovate. There are ways to mitigate this cost, and the platforms we choose to run on modern data platforms will work to decrease this negative; we will also have to leverage automation which will again have a tradeoff requiring us to have skilled technicians to implement in an effective way. Overall, the benefits outweigh any negatives; the increase in flexibility and ability to innovate and solve business issues is dramatic.
Name Plated Logical Architecture
So all of that above is great, but what are we actually going to build in Azure?
Oh, okay, so you want to discuss the name-plated technologies to be used in our architecture. Well, it is pretty straightforward and pulled almost straight from the Azure Architecture Center website. Below is my version of a Modern Data Platform; it might be slightly different one way or another, but it implements all of the different capabilities depicted above in the Logical architecture. There is some duplication in capability between Azure Data Bricks and the Azure Synapse components. The reason for this is I feel both bring something to the table the other does not currently. Long term, if I pulled this physical architecture together in, say, 18 months to 2 years, I may only have one or the other. Synapse major role in this architecture is to serve as a friendly T-SQLish interface to our data. Large and small organizations have Microsoft SQL Server experience and have the tools sets already deployed to interact with MS SQL Server, which brings comfort to a largely new environment. Leveraging the experience and comfort to help accelerate the adoption of this new Modern Data Platform is key to its success across both technical portions and business portions of the organization.
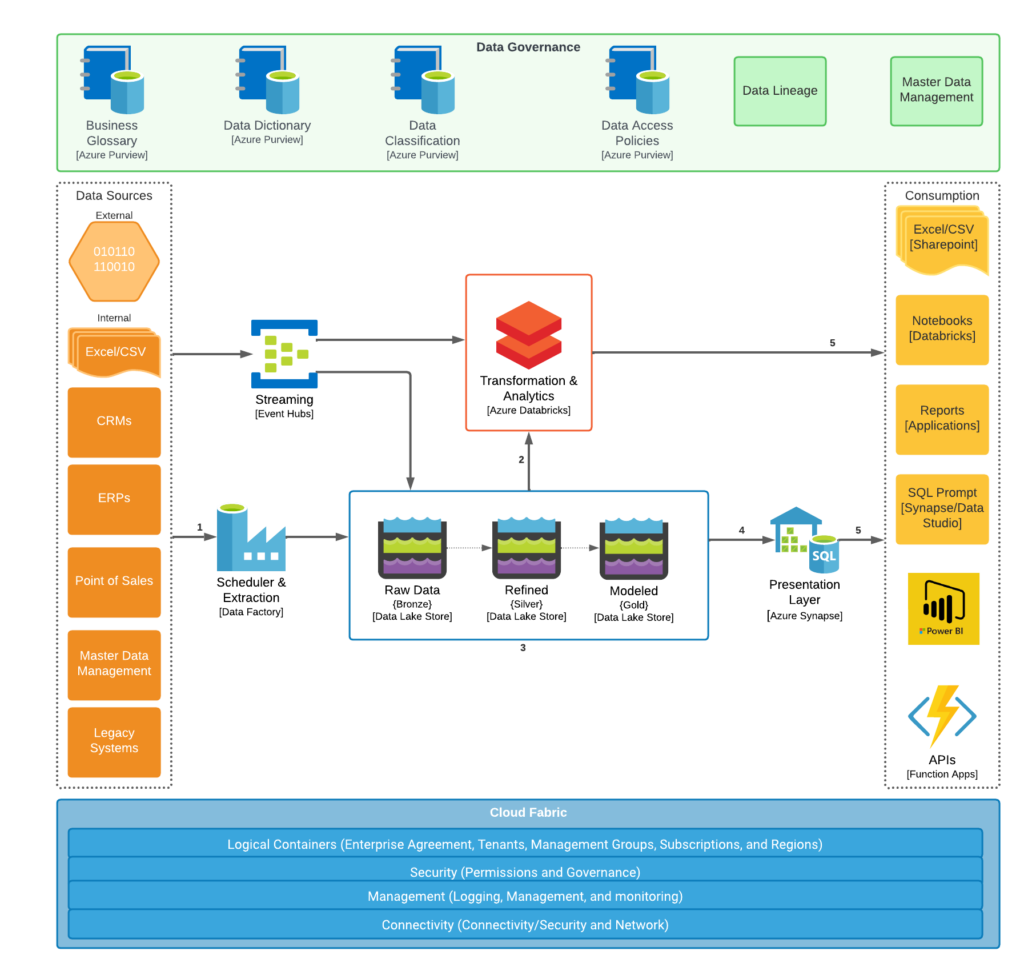
You may have noticed that the Cloud Fabric block is still logical in nature, and no name plating has been provided. This area is pretty vast, and we will be walking through each layer in a separate post. Simply placing a few technology names in this block would be a disservice to the amount of time and energy required here.
I’m not going to spend a great amount of time discussing the details of the name-plated technologies themselves. Microsoft provides so much information on these tools, covering them from an introduction to detailed examples of how they can be used. So instead, I will take a little time to match them up to the capabilities listed in the Logical Architecture.
- Ingestion – Streaming – Event Hub & Azure Data Bricks
- Ingestion – Batch – Azure Data Factory
- Storage – Azure Storage
- Processing – Data Engineering (Modeling, Enrichment, Tokenization, ect.) – Azure Data Bricks
- Processing – Predictive Analytics, & Prescriptive Analytics – Azure Data Bricks & Machine Learning Services Workspaces &. Cognitive Services
- Processing – SQL Layer – Azure Synapse
Well, that’s it, short and sweet. Now you know what we are building and why. Sorry, there is no code to look at; we will get to that next time in Part IV.